Kaushal Gohel

In 12 months, I evolved from struggling with data to proficiency in Machine Learning Engineering, mastering core concepts and multiple libraries with mentorship.
I leverage MLOps for efficiency and use deep learning and neural networks to extract insights from complex datasets, effectively tackling industry challenges.
View My LinkedIn Profile
NATURAL LANGUAGE PROCESSING (NLP) PROJECTS
Sentiment Analysis
In this project, I developed a sentiment analysis model to classify user reviews into categories like Positive, Negative, Neutral, and Irrelevant. I performed extensive text preprocessing, including cleaning, stemming, and stopword removal, followed by feature extraction using TF-IDF. I then trained and evaluated multiple machine learning models, such as Logistic Regression, SVC, Random Forest, XGBoost, and CatBoost, along with ensemble techniques like Bagging and Voting Classifiers. The models were assessed based on metrics like accuracy, precision, recall, and F1 score, with results visualized through confusion matrices. This project demonstrates my skills in natural language processing, machine learning model selection, and performance evaluation.
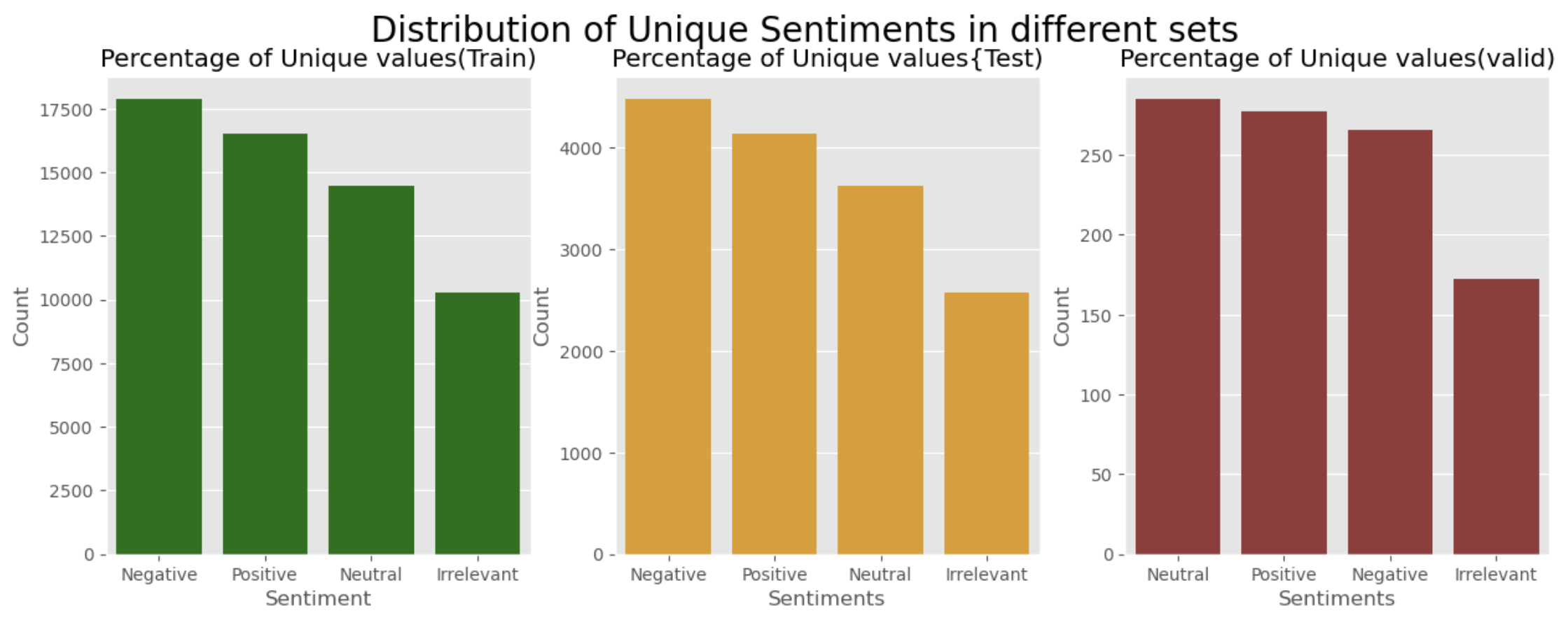
Analyzed sentiment distribution across datasets to ensure balanced representation for effective sentiment analysis. Visualized sentiments to guide preprocessing and model training.
Customer Sentiment Trends with VADER Analysis
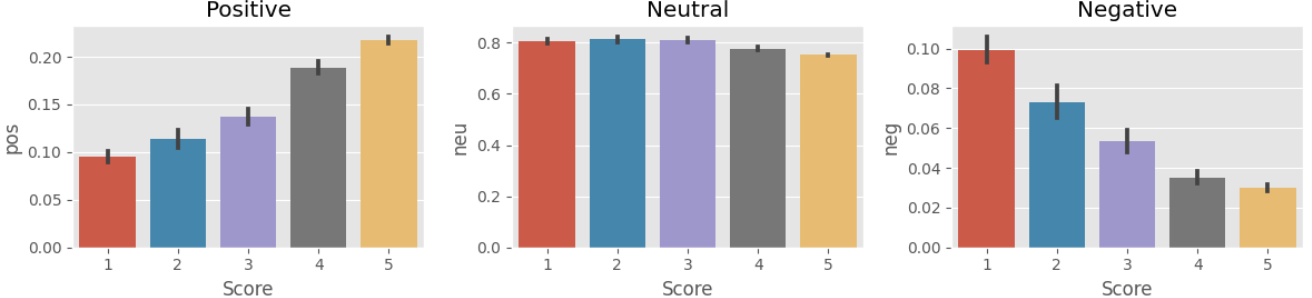
This project focused on sentiment analysis using VADER to categorize customer reviews based on their polarity (positive, neutral, negative). I handled data preprocessing, sentiment scoring, and visualizing sentiment trends across various score levels. By addressing the challenge of visual clarity, I ensured the insights were intuitive and actionable for further analysis.
This plot compares positive, neutral, and negative sentiment distributions across review scores. I tackled the challenge of visual clarity by organizing the data into subplots and using a clean layout, ensuring each sentiment is easy to interpret.
Text Classification
I developed a spam classification system using Natural Language Processing (NLP) and Machine Learning techniques, designed to accurately distinguish between spam and legitimate messages. The project began with comprehensive data cleaning and preprocessing, including the removal of duplicates, tokenization, stop word removal, and stemming, ensuring the dataset was optimized for analysis. I conducted detailed exploratory data analysis (EDA), visualizing patterns such as word frequency, character counts, and other text properties to gain deeper insights into the dataset. To convert the textual data into a machine-readable format, I employed CountVectorizer for feature extraction. The classification model, built using a Multinomial Naive Bayes algorithm, achieved a test accuracy of 98.4%. The model’s performance was rigorously evaluated using precision, recall, F1-score, and a confusion matrix, confirming its effectiveness for real-world applications. This project showcases my ability to handle unstructured data, apply NLP techniques, and build robust predictive models, reflecting my skills in developing practical machine learning solutions.
I analyzed a spam classification dataset and visualized word frequencies using a word cloud. The result highlights common spam related terms line “free”, “text” and “call”.
.png?raw=true)